布隆过滤器 2023-02-09 21:42 ### 简介 布隆过滤器是一种空间高效概率性的数据结构。该数据结构用来判断某个元素是否在某个集合中。若返回true,则可能在集合中;若返回false,则一定不在集合中。 示例: 某一个存储ip地址的集合,有十亿个ip,现给出一个ip,判断此ip是否在ip集合里。 若经过布隆过滤器计算后,返回false,则这个Ip一定不在这个ip集合中;若返回true,则这个ip可能在ip集合中。 ### 原理 存入元素时,将一个元素经过多次hash,多个hash值对应位置的索引值置为1。想要知道某个元素是否在集合里时,只需将该元素同样经过多次hash,判断多个hash值对应位置索引值是1还是0。如果都是1,则可能在集合中,如果有一个是0,则一定不再集合中。 ### 应用场景 网站爬虫应用中进行URL去重(不存在于布隆过滤器中的URL必定是未爬取过的URL) 防火墙应用中IP黑名单判断(不局限于IP黑名单,通用的黑名单判断场景基本都可以使用布隆过滤器,不存在于布隆过滤器中的IP必定是白名单) 用于规避缓存穿透(不存在于布隆过滤器中的KEY必定不存在于后置的缓存中) ### Java实现 hash函数: ```java package com.example.demo.core.Bloom; import java.util.Objects; public class HashFunction2 { /** * 布隆过滤器容量 */ private final int m; /** * 种子 */ private final int seed; public HashFunction2(int m, int seed) { this.m = m; this.seed = seed; } public int hash(String element) { if (Objects.isNull(element)) { return 0; } int result = 1; int len = element.length(); for (int i = 0; i < len; i++) { result = seed * result + element.charAt(i); } // 这里确保计算出来的结果不会超过m return (m - 1) & result; } } ``` 布隆过滤器: ```java package com.example.demo.core.Bloom; import java.util.BitSet; import java.util.Objects; /** * 简单的布隆过滤器实现,和 SimpleBloomFilter1 基本相同,可读性更强一些。 * @author hanxu03 */ public class BloomFilter2 { private static final int[] K_SEED_ARRAY = {5, 7, 11, 13, 31, 37, 61, 67}; private static final int MAX_K = K_SEED_ARRAY.length; private final int m; private final int k; private final BitSet bitSet; private final HashFunction2[] hashFunction2s; public BloomFilter2(int m, int k) { this.k = k; if (k <= 0 && k > MAX_K) { throw new IllegalArgumentException("k = " + k); } this.m = m; this.bitSet = new BitSet(m); hashFunction2s = new HashFunction2[k]; for (int i = 0; i < k; i++) { hashFunction2s[i] = new HashFunction2(m, K_SEED_ARRAY[i]); } } public void addElement(String element) { //添加元素时需要多次计算hash算法 for (HashFunction2 hashFunction2 : hashFunction2s) { bitSet.set(hashFunction2.hash(element), true); } } public boolean contains(String element) { if (Objects.isNull(element)) { return false; } boolean result = true; for (HashFunction2 hashFunction2 : hashFunction2s) { //如果每个位置上都为true,则有可能存在,返回true;若有一个是false,则必定不存在,返回false。 result = result && bitSet.get(hashFunction2.hash(element)); } return result; } public int m() { return m; } public int k() { return k; } public static void main(String[] args) { BloomFilter2 bf = new BloomFilter2(24, 3); bf.addElement("throwable"); bf.addElement("throwx"); System.out.println(bf.contains("throwable")); // true } } ``` ### guava工具 依赖: ```xml <dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>31.0.1-jre</version> </dependency> ``` ```java package com.example.demo.core.Bloom.guava; import com.google.common.hash.BloomFilter; import com.google.common.hash.Funnel; import java.nio.charset.Charset; /** * @author hanxu03 * com.google.guava 的布隆过滤器,使用Demo */ public class GuavaBloomTest { // 预计元素个数 private long size = 1024 * 1024; private BloomFilter<String> bloom = BloomFilter.create((Funnel<String>) (from, into) -> { // 自定义过滤条件 此处不做任何过滤 into.putString((CharSequence) from, Charset.forName("UTF-8")); }, size); public void fun() { // 往过滤器中添加元素 bloom.put("布隆过滤器"); // 查询 boolean mightContain = bloom.mightContain("布隆过滤器"); System.out.println(mightContain); } public static void main(String[] args) { GuavaBloomTest blBoolmTest = new GuavaBloomTest(); blBoolmTest.fun(); boolean b = blBoolmTest.bloom.put("测试元素"); System.out.println(b); boolean result = blBoolmTest.bloom.mightContain("测试元素1"); System.out.println(result); } } ``` ### redission工具 依赖: ```xml <dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> <version>3.15.1</version> </dependency> ``` ```java package com.example.demo.core.Bloom.redisson; import org.redisson.Redisson; import org.redisson.api.RBloomFilter; import org.redisson.api.RedissonClient; import org.redisson.config.Config; public class RedissonBloomFilter { public static void main(String[] args) { Config config = new Config(); config.useSingleServer() .setAddress("redis://127.0.0.1:6379").setPassword("hanxu"); RedissonClient redissonClient = Redisson.create(config); RBloomFilter<String> bloomFilter = redissonClient.getBloomFilter("ipBlockList"); // 第一个参数expectedInsertions代表期望插入的元素个数,第二个参数falseProbability代表期望的误判率,小数表示 bloomFilter.tryInit(100000L, 0.03D); bloomFilter.add("127.0.0.1"); bloomFilter.add("192.168.1.1"); System.out.println("192.168.1.1的结果是:" + bloomFilter.contains("192.168.1.1")); // true System.out.println("192.168.1.2的结果是:" + bloomFilter.contains("192.168.1.2")); // false redissonClient.shutdown(); } } ``` ### m、k、n的关系 ```java package com.example.demo.core.Bloom; import java.math.BigDecimal; import java.math.RoundingMode; /** * 参考链接: https://www.throwx.cn/2021/08/21/bloom-filter/#%E5%B8%83%E9%9A%86%E8%BF%87%E6%BB%A4%E5%99%A8%E7%AE%80%E4%BB%8B * 布隆过滤器 初始化比特数组容量m,需要添加到布隆过滤器的元素数量n,散列函数个数k 的关系式 * 误判率ε (Epsilon,代表False Positive Rate) * <p> * 误判率ε的估算值为:[1 - e^(-kn/m)]^k * 最优散列函数数量k的推算值:对于给定的m和n,当k = m/n * ln2的时候,误判率ε最低 * 推算初始化比特容量m的值,当k = m/n * ln2的时候,m >= n * log2(e) * log2(1/ε) * @author hanxu03 */ public class BloomFilterParamGenerator { /** * 计算误判率 * * @param m * @param n * @param k * @return */ public BigDecimal falsePositiveRate(int m, int n, int k) { double temp = Math.pow(1 - Math.exp(Math.floorDiv(-k * n, m)), k); return BigDecimal.valueOf(temp).setScale(10, RoundingMode.FLOOR); } /** * 要达到最小误判率,应设置的散列函数数量k值 * * @param m * @param n * @return */ public BigDecimal kForMinFalsePositiveRate(int m, int n) { BigDecimal k = BigDecimal.valueOf(Math.floorDiv(m, n) * Math.log(2)); return k.setScale(10, RoundingMode.FLOOR); } /** * 计算比特数组容量m * * @param n * @param falsePositiveRate * @return */ public BigDecimal bestM(int n, double falsePositiveRate) { double temp = log2(Math.exp(1) + Math.floor(1 / falsePositiveRate)); return BigDecimal.valueOf(n).multiply(BigDecimal.valueOf(temp)).setScale(10, RoundingMode.FLOOR); } public double log2(double x) { return Math.log(x) / Math.log(2); } public static void main(String[] args) { BloomFilterParamGenerator generator = new BloomFilterParamGenerator(); System.out.println(generator.falsePositiveRate(2, 1, 2)); // 0.3995764008 System.out.println(generator.kForMinFalsePositiveRate(32, 1)); // 22.1807097779 System.out.println(generator.bestM(1, 0.3995764009)); // 2.2382615950 } } ``` ### 各种布隆 **初代**: > 初代不支持删除,如果删除元素,则以后再判断元素是否存在于集合中,就会出现误判(误判:“只要有一个索引位置上的值是0,那么该元素一定不存在集合中”不成立了)。 只要有一个索引位置上的值是0,那么该元素一定不存在集合中。 如果计算出来的多个索引值位置上的元素全位1,那么该元素可能存在于集合中。 **计数布隆过滤器 CBF**( Counting Bloom filter ): 网上很多说“基本定理和初代一样,只是支持了删除。由于Counter的存在,使删除操作能够进行,删除元素后不会再出现误判。” 但实际上计数布隆过滤器不支持删除,因为布隆过滤器无法准确判断元素**一定存在**于集合中。 如果某个值不存在于集合中,那么对其删除就会删掉布隆过滤器中其他元素的计数值,从而导致其他元素查询时的误判; 如果通过其他方法确定了某个值一定存在于集合中,然后通过布隆过滤器进行删除,则不能保证后续该值在布隆过滤器中的查询一定返回false(冲突)。 所以,也不能说CBF就支持删除操作了。 CBF想删元素,有条件: 1、必须使用其他方法确保要删除的元素存在于集合中。 2、删除后不能保证此元素通过布隆过滤器查询时返回false。 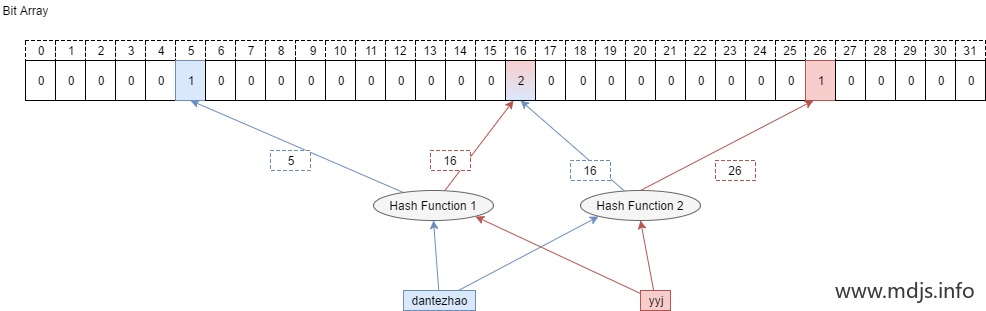 ### 总结 布隆过滤器的优势: 布隆过滤器相对于其他数据结构在时空上有巨大优势,占用内存少,查询和插入元素的时间复杂度都是O(k) 可以准确判断元素不存在于布隆过滤器中的场景 散列函数可以独立设计 布隆过滤器不需要存储元素本身,适用于某些数据敏感和数据严格保密的场景 布隆过滤器的劣势: 不能准确判断元素必定存在于布隆过滤器中的场景,存在误判率,在k和m固定的情况下,添加的元素越多,误判率越高 没有存储全量的元素,对于一些准确查询或者准确统计的场景不适用 原生的布隆过滤器无法安全地删除元素(删除元素时需要删除某几个特定索引位置的比特值,而这些索引位置上的值有可能被其他元素共用) ### 参考: [冷饭新炒-布隆过滤器](https://www.throwx.cn/2021/08/21/bloom-filter) [CBF为什么不支持删除(见评论区)](https://zhuanlan.zhihu.com/p/43263751) [CBF中Counter大小的选择](https://cloud.tencent.com/developer/article/1136056) --END--
发表评论